
#46 - Thought Experiment - Your Data Debt Just Became Less Worrying
What if, with AI, you COULD deliver unified insights WITHOUT unifying your data?

Last week I challenged your “we’re flexible” identity as hidden operational debt.
This week: the master data nightmare you’ve been funding for years that AI just made optional for 80% of your use cases.
Here’s this week’s provocation.
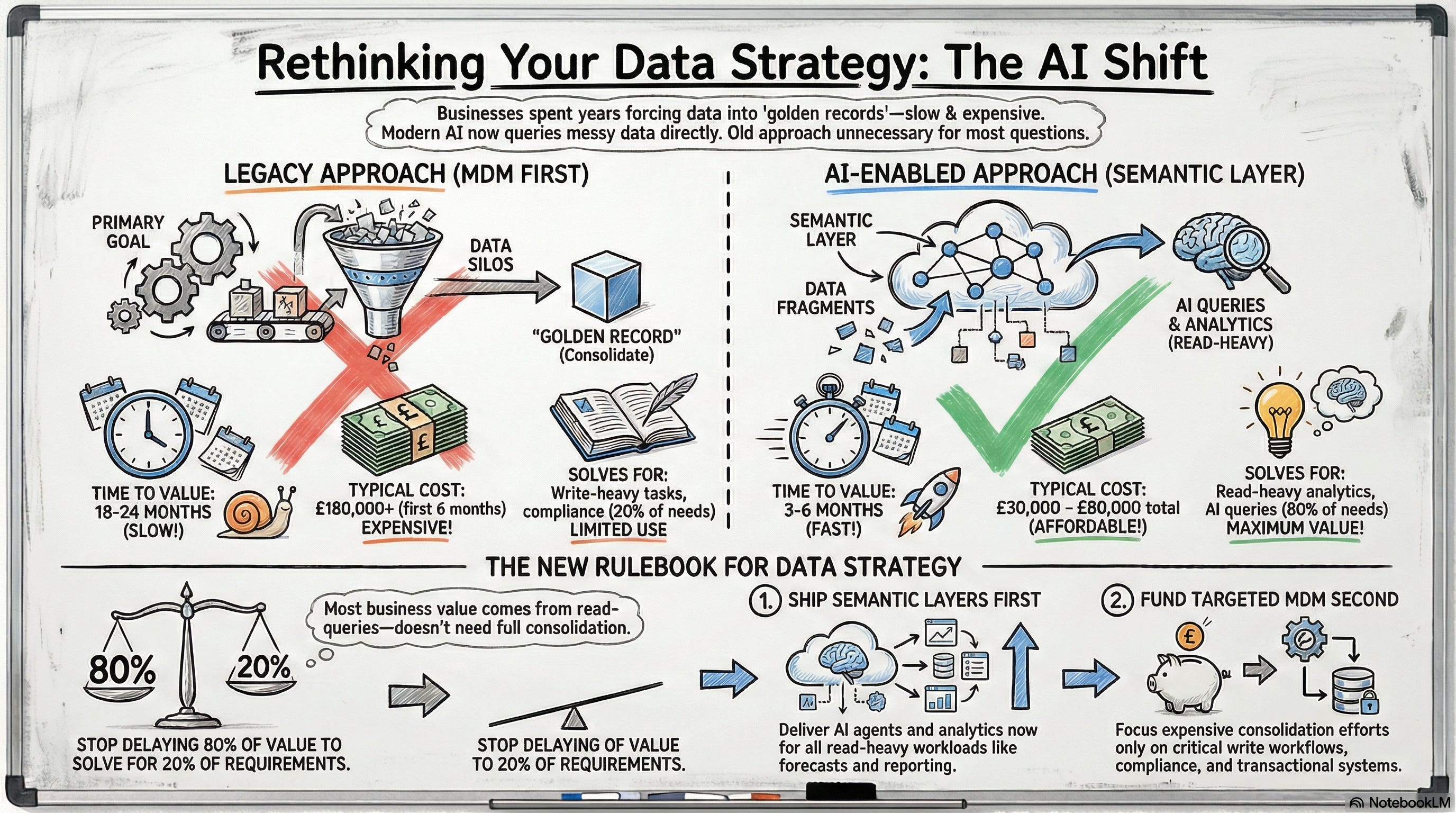
Your CDO just kicked off another master data management initiative. The goal: finally achieve that unified customer 360 view.
Six months in, you’ve spent £180K on consultants, alienated three business units arguing over who owns “customer,” and you still have the same customer represented differently across billing, CRM, support, ERP, and marketing automation. Meanwhile, one of your business units stood up a semantic layer with an AI agent that queries across all those systems without touching them and delivers answers your golden record project won’t ship for another 18 months.
See this Reddit thread where a data engineer describes the hell of trying to integrate enterprise data:
“Salesforce uses 6-digit customer IDs but we can never remember those, so here’s this Excel spreadsheet with the client alphanumeric codes that we actually use”.
Another engineer on the same thread reports dealing with 20 petabytes of binary data with no schema control, stored alongside three separate copies of sample databases.
- What if the problem isn’t that your data is messy?
- What if the problem is that you’re still trying to solve data unification the way you did in 2015, when the constraint was query engines that couldn’t handle semantic abstraction?
We will explore this with this framing in mind:
Not Ask: “How do we clean up our data to use AI?”
But Ask: “If AI can query across fragmented data sources using semantic understanding, why are we still trying to force everything into one golden record?”
Legacy Assumption
Enterprise data quality is solved by consolidation. You unify disparate systems into a single source of truth, a golden record, a customer 360 view. Master data management means reconciling every customer, product, and vendor record so everyone works from the same database.
The assumption: reporting and analytics engines need clean, structured, deduplicated data in one place to function. If billing says the customer is “Acme Corp” and CRM says “ACME Corporation” and support logs it as “Acme UK Ltd,” your reports break. Your forecasts are wrong. Your operations team sends invoices to the wrong entity.
So you fund multi-year MDM programs. You hire consultants to map schemas. You fight political battles over data ownership. You build ETL pipelines to reconcile records nightly. That assumption held when query engines were brittle and required perfectly normalized schemas. When “customer 360” meant literally consolidating every record into one row in one table.
But that constraint is gone now.
AI-Enabled Inversion
AI agents don’t need golden records for read queries. They need semantic understanding. A well-configured agent with a semantic layer can query “Acme Corp” across billing, CRM, support, and ERP, recognize they’re the same entity through contextual inference, and synthesize answers without anyone touching the underlying systems.
Research shows semantic layers reduce LLM hallucinations by over 50%, with text-to-SQL implementations achieving accuracy rates approaching 99.8% when leveraging semantic context.
Harvard Business Review research on agentic AI emphasizes that the technology’s power depends entirely on semantic data layers that unify and deliver trusted data at enterprise scale. As one researcher notes, “We’re now creating agent organizations where intelligence needs to be codified so machine agents and humans can sing off the same data page”.
Here’s the inversion: you don’t solve fragmentation by consolidation anymore for read-heavy analytics. You solve it by abstraction.
Build the semantic layer that lets AI understand what “customer” means across six different schemas, and suddenly your multi-year MDM program becomes optional for 80% of your business questions. The old game was “clean the data so reports work.” The new game is “teach the AI what the business means so it can query messy data intelligently.”
What if you could deliver unified insights in 3-6 months instead of 18-24?
Forcing Question
If AI can now query across fragmented sources using semantic understanding, why are you funding 18-month consolidation programs when 80% of your business value comes from read queries that semantic layers solve in 3-6 months?
Real Cost
Let’s start with what you think the cost is: annoying reconciliation work, occasional duplicate customer records, slow month-end closes because finance has to manually merge spend data from three ERPs, etc.
Here’s what it costs. McKinsey’s research shows AI tools are now automating the identification, correction, and remediation of data quality issues that used to require armies of data stewards. Organizations that haven’t adopted this approach are bleeding coordination costs daily while their competitors ship AI-powered insights in months, not years.
But here’s the catch your CDO will rightfully point out that semantic layers solve the READ problem beautifully, but they don’t solve the WRITE problem. She will ask: When a customer updates their billing address, which system is authoritative?
- GDPR’s right to erasure requires knowing where ALL copies of data live.
- Without integrated master data, you have little visibility into which downstream systems are processing personal data, making guaranteed deletion nearly impossible.
- Semantic layers query across fragmented sources.
- They don’t tell you where to write updates or delete records.
And there’s the performance question.
- Federated queries generally have higher latency than queries against optimized databases, with overhead from network communication, query translation, and result aggregation.
- When your exec dashboard needs sub-second response times and you’re hitting six different databases, query performance can degrade significantly even with intelligent caching and pre-computation.
So what’s the actual trade?
- Semantic layers let you ship AI agents and analytics NOW for read-heavy workloads without waiting 18 months for consolidation.
- But you still need MDM for transactional consistency, regulatory compliance, and authoritative writes.
- The question isn’t “semantic layer OR master data.”
- It’s “which 80% of your value comes from reads that semantic layers unlock immediately, versus which 20% requires true consolidation?”
Next Conversation
Do this with your CDO, CFO, and a data engineer in a 90-minute session:
Segment your data use cases by read vs. write.
- Pull the last quarter’s top 20 business questions that drove decisions: forecasts, pipeline reviews, customer health scores, spend analysis.
- Count how many required READING data from multiple systems versus WRITING updates back.
- If 70-80% are READ queries, semantic layers deliver immediate value without touching your MDM roadmap.
Run the semantic test on your highest-value questions.
- Pick the five questions executives ask most often: “What did Acme Corp spend with us last quarter?” or “Which customers are at renewal risk?”
- Ask your data team: “If we built a semantic layer that mapped business terms to our actual schemas, could an AI agent answer these WITHOUT consolidating the underlying data?”
- If yes, ask why you’re delaying value for 18 months.
Identify your true consolidation requirements.
- Where do you genuinely need a golden record? Possibly - GDPR deletion requests, financial close processes, transactional systems that update customer data, regulatory reporting that can’t tolerate eventual consistency.
- Calculate what percentage of your MDM budget those represent.
- If it’s 20-30%, why are you funding the entire program before shipping any AI capability?
Calculate the opportunity cost with honest performance assumptions.
- Semantic layer implementation: £30K-£80K, 3-6 month build.
- But add query latency costs. Studies show federated queries can lag local storage, though caching and AI routing can slash this by 40-77%.
- Compare that to your MDM program in year two with zero production use cases.
- Even with performance trade-offs, which path delivers business value faster?
Usually, the blocker is “we thought we had to consolidate first.”
That’s the legacy assumption.
The new rule:
“Ship semantic layers for read-heavy analytics and AI agents now. Fund targeted MDM for write workflows, compliance, and transactional consistency. Stop delaying 80% of your value to solve for 20% of your requirements.”
If this scenario feels uncomfortably plausible, let’s talk. I and my team at Intelstack work with leaders at mid-size enterprises to map what AI makes possible and what it makes obsolete before your competition figures it out.